
In this post, I will explain you about Cluster Analysis, The process of grouping objects/individuals together in such a way that objects/individuals in one group are more similar than objects/individuals in other groups.
For example, from a ticket booking engine database identifying clients with similar booking activities and group them together (called Clusters). Later these identified clusters can be targeted for business improvement by issuing special offers, etc.
Cluster Analysis falls into Unsupervised Learning algorithms, where in Data to be analyzed will be provided to a Cluster analysis algorithm to identify hidden patterns within as shown in the figure below.
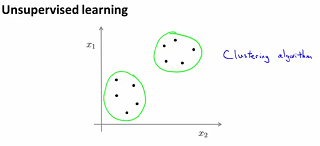 In the image above, the cluster algorithm has grouped the input data into two groups.
There are 3 Popular Clustering algorithms, Hierarchical Cluster Analysis, K-Means Cluster Analysis, Two-step Cluster Analysis, of which today I will be dealing with K-Means Clustering.
In the image above, the cluster algorithm has grouped the input data into two groups.
There are 3 Popular Clustering algorithms, Hierarchical Cluster Analysis, K-Means Cluster Analysis, Two-step Cluster Analysis, of which today I will be dealing with K-Means Clustering.
Explaining k-Means Cluster Algorithm:
In K-means algorithm, k stands for the number of clusters (groups) to be formed, hence this algorithm can be used to group known number of groups within the Analyzed data.
K Means is an iterative algorithm and it has two steps. First is a Cluster Assignment Step, and second is a Move Centroid Step.
CLUSTER ASSIGNMENT STEP: In this step, we randomly chose two cluster points (red dot & green dot) and we assign each data point to one of the two cluster points whichever is closer to it. (Top part of the below image)
MOVE CENTROID STEP: In this step, we take the average of the points of all the examples in each group and move the Centroid to the new position i.e. mean position calculated. (Bottom part of the below image)
The above steps are repeated until all the data points are grouped into 2 groups and the mean of the data points at the end of Move Centroid Step doesn’t change.

By repeating the above steps the final output grouping of the input data will be obtained.

For example, from a ticket booking engine database identifying clients with similar booking activities and group them together (called Clusters). Later these identified clusters can be targeted for business improvement by issuing special offers, etc.
Cluster Analysis falls into Unsupervised Learning algorithms, where in Data to be analyzed will be provided to a Cluster analysis algorithm to identify hidden patterns within as shown in the figure below.

Explaining k-Means Cluster Algorithm:
In K-means algorithm, k stands for the number of clusters (groups) to be formed, hence this algorithm can be used to group known number of groups within the Analyzed data.
K Means is an iterative algorithm and it has two steps. First is a Cluster Assignment Step, and second is a Move Centroid Step.
CLUSTER ASSIGNMENT STEP: In this step, we randomly chose two cluster points (red dot & green dot) and we assign each data point to one of the two cluster points whichever is closer to it. (Top part of the below image)
MOVE CENTROID STEP: In this step, we take the average of the points of all the examples in each group and move the Centroid to the new position i.e. mean position calculated. (Bottom part of the below image)
The above steps are repeated until all the data points are grouped into 2 groups and the mean of the data points at the end of Move Centroid Step doesn’t change.

Cluster Analysis on Accidental Deaths by Natural Causes in India using R
Implementation of k-Means Cluster algorithm can readily downloaded as R Package, CLUSTER . Using the package we shall do cluster analysis of Accidents deaths in India by Natural Causes.
Steps implemented will be discussed as below:
The data for our analysis was downloaded from www.data.gov.in.
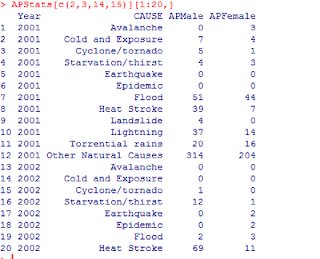
Between 2001 & 2012. Input data is displayed as below:

For any cluster analysis, all the features have to be converted into numerical & the larger values in the Year Columns are converted to z-score for better results.
Run Elbow method (code available below) is run to find the optimal number of clusters present within the data points.
Run the K-means cluster method of the R package & visualize the results as below:



Code:
#Fetch
data
data=
read.csv("Cluster Analysis.csv")
APStats =
data[which(data$STATE == 'ANDHRA PRADESH'),]
APMale =
rowSums(APStats[,4:8])
APFemale
= rowSums(APStats[,9:13])
APStats[,'APMale']
= APMale
APStats[,'APFemale']
= APFemale
data =
APStats[c(2,3,14,15)]
library(cluster)
library(graphics)
library(ggplot2)
#factor
the categorical fields
cause =
as.numeric(factor(data$CAUSE))
data$CAUSE
= cause
#Z-score
for Year column
z = {}
m =
mean(data$Year)
sd =
sd(data$Year)
year =
data$Year
for(i in
1:length(data$Year)){
z[i] =
(year[i] - m)/sd
}
data$Year
= as.numeric(z)
#Calculating
K-means - Cluster assignment & cluster group steps
cost_df
<- data.frame()
for(i in
1:100){
kmeans<-
kmeans(x=data, centers=i, iter.max=100)
cost_df<-
rbind(cost_df, cbind(i, kmeans$tot.withinss))
}
names(cost_df)
<- c("cluster", "cost")
#Elbow
method to identify the idle number of Cluster
#Cost
plot
ggplot(data=cost_df,
aes(x=cluster, y=cost, group=1)) +
theme_bw(base_family="Garamond")
+
geom_line(colour
= "darkgreen") +
theme(text
= element_text(size=20)) +
ggtitle("Reduction
In Cost For Values of 'k'\n") +
xlab("\nClusters")
+
ylab("Within-Cluster
Sum of Squares\n")
clust =
kmeans(data,5)
clusplot(data,
clust$cluster, color=TRUE, shade=TRUE,labels=13, lines=0)
data[,'cluster']
= clust$cluster
head(data[which(data$cluster
== 5),])
Hello! This is kind of off topic but I need some guidance from an established blog. Is it very difficult to set up your own blog? I'm not very techincal but I can figure things out pretty fast. I'm thinking about setting up my own but I'm not sure where to begin. Do you have any points or suggestions? Thank you productivity solutions grant (psg)
ReplyDeleteGood day! Do you know if they make any plugins to safeguard against hackers? I'm kinda paranoid about losing everything I've worked hard on. Any recommendations?
ReplyDeleteaffordable web design
I needed to put you this little word so as to give many thanks again regarding the pretty guidelines you have shown on this site. It's quite generous with you giving openly what many individuals could have offered as an e book to end up making some profit for themselves, particularly since you could possibly have done it in the event you wanted. The pointers also acted to be a easy way to be certain that some people have the identical dreams the same as my own to grasp a whole lot more related to this condition. I think there are many more enjoyable occasions up front for many who discover your website.
ReplyDeleteseo agencies singapore
Great blog here! Also your website loads up fast! What web host are you using? Can I get your affiliate link to your host? I wish my website loaded up as quickly as yours lol. jc maths tuition
ReplyDeleteHi there, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot of spam remarks? If so how do you protect against it, any plugin or anything you can recommend? I get so much lately it's driving me crazy so any help is very much appreciated.
ReplyDeleteGet sales via google
I savour, result in I found exactly what I used to be taking a look for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye. rebranded its online store front
ReplyDeleteHello There. I found your blog using msn. This is a really well written article. I’ll make sure to bookmark it and return to read more of your useful info. Thanks for the post. I will certainly return.
ReplyDeleteonline selling platform singapore
obviously like your website but you have to check the spelling on quite a few of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth nevertheless I will certainly come back again. best online shopping sites
ReplyDeleteTo guarantee that guests of your site will transform into leads and after that into clients, you have to contract visit specialists that will really cooperate with them.artificial intelligence course
ReplyDeleteHi, i think that i saw you visited my web site so i came to “return the favor”.I'm trying to find things to enhance my website!I suppose its ok to use some of your ideas!! Copper Round Bar
ReplyDelete3D rendering examples the creation of an idea requested by a client it may be a real-world object or an imaginary that represented in a sketch say, architectural, interior design or products.
ReplyDelete3d architectural rendering