
As a part of Twitter Data Analysis, So far I have
completed Movie
review using R & Document
Classification using R. Today we will be dealing with discovering
topics in Tweets, i.e. to mine the tweets data to discover underlying topics–
approach known as Topic Modeling.

 Conclusion:
Conclusion:
SourceCode:
library("tm")
library("wordcloud")
library("slam")
library("topicmodels")
#Load Text
con <- file("tweets.txt", "rt")
tweets = readLines(con)
#Clean Text
tweets = gsub("(RT|via)((?:\\b\\W*@\\w+)+)","",tweets)
tweets = gsub("http[^[:blank:]]+", "", tweets)
tweets = gsub("@\\w+", "", tweets)
tweets = gsub("[ \t]{2,}", "", tweets)
tweets = gsub("^\\s+|\\s+$", "", tweets)
tweets <- gsub('\\d+', '', tweets)
tweets = gsub("[[:punct:]]", " ", tweets)
corpus = Corpus(VectorSource(tweets))
corpus = tm_map(corpus,removePunctuation)
corpus = tm_map(corpus,stripWhitespace)
corpus = tm_map(corpus,tolower)
corpus = tm_map(corpus,removeWords,stopwords("english"))
tdm = DocumentTermMatrix(corpus) # Creating a Term document Matrix
# create tf-idf matrix
term_tfidf <- tapply(tdm$v/row_sums(tdm)[tdm$i], tdm$j, mean) * log2(nDocs(tdm)/col_sums(tdm > 0))
summary(term_tfidf)
tdm <- tdm[,term_tfidf >= 0.1]
tdm <- tdm[row_sums(tdm) > 0,]
summary(col_sums(tdm))
#Deciding best K value using Log-likelihood method
best.model <- lapply(seq(2, 50, by = 1), function(d){LDA(tdm, d)})
best.model.logLik <- as.data.frame(as.matrix(lapply(best.model, logLik)))
#calculating LDA
k = 50;#number of topics
SEED = 786; # number of tweets used
CSC_TM <-list(VEM = LDA(tdm, k = k, control = list(seed = SEED)),VEM_fixed = LDA(tdm, k = k,control = list(estimate.alpha = FALSE, seed = SEED)),Gibbs = LDA(tdm, k = k, method = "Gibbs",control = list(seed = SEED, burnin = 1000,thin = 100, iter = 1000)),CTM = CTM(tdm, k = k,control = list(seed = SEED,var = list(tol = 10^-4), em = list(tol = 10^-3))))
#To compare the fitted models we first investigate the values of the models fitted with VEM and estimated and with VEM and fixed
sapply(CSC_TM[1:2], slot, "alpha")
sapply(CSC_TM, function(x) mean(apply(posterior(x)$topics, 1, function(z) - sum(z * log(z)))))
Topic <- topics(CSC_TM[["VEM"]], 1)
Terms <- terms(CSC_TM[["VEM"]], 8)
Terms
What is Topic Modeling?
A statistical approach for discovering “abstracts/topics” from a collection of text documents based on statistics of each word. In simple terms, the process of looking into a large collection of documents, identifying clusters of words and grouping them together based on similarity and identifying patterns in the clusters appearing in multitude.
A statistical approach for discovering “abstracts/topics” from a collection of text documents based on statistics of each word. In simple terms, the process of looking into a large collection of documents, identifying clusters of words and grouping them together based on similarity and identifying patterns in the clusters appearing in multitude.
Consider the below Statements:
- I love
playing cricket.
- Sachin is my
favorite cricketer.
- Titanic is
heart touching movie.
- Data
Analytics is next Future in IT.
- Data
Analytics & Big Data complements each other.
When we apply Topic Modeling to the above statements,
we will be able to group statement 1&2
as Topic-1 (later we can
identify that the topic is Sport), statement 3 as Topic-2 (topic is Movies), statement 4&5 as Topic-3 (topic is data Analytics).
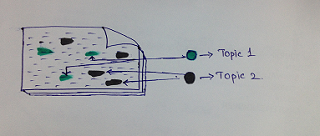

{kind=link}
fig:
Identifying topics in Documents and classifying as Topic 1 & Topic 2
Latent Dirichlet
Allocation algorithm (LDA):
Topic Modeling can be achieved by using Latent Dirichlet Allocation algorithm. Not going into the nuts & bolts of the Algorithm, LDA automatically learns itself to assign probabilities to each & every word in the Corpus and classify into Topics. A simple explanation for LDA could be found here:
Topic Modeling can be achieved by using Latent Dirichlet Allocation algorithm. Not going into the nuts & bolts of the Algorithm, LDA automatically learns itself to assign probabilities to each & every word in the Corpus and classify into Topics. A simple explanation for LDA could be found here:
Twitter Data
Analysis Using LDA:
Steps Involved:
- Fetch tweets
data using ‘twitteR’
package.
- Load the data
into the R environment.
- Clean the
Data to remove: re-tweet information, links, special characters,
emoticons, frequent words like is, as, this etc.
- Create a Term
Document Matrix (TDM) using ‘tm’
Package.
- Calculate TF-IDF i.e. Term
Frequency Inverse Document Frequency for all the words in word matrix
created in Step 4.
- Exclude all
the words with tf-idf <= 0.1, to remove all the words which are less
frequent.
- Calculate the
optimal Number of topics (K) in the Corpus using log-likelihood method for
the TDM calculated in Step6.
- Apply LDA
method using ‘topicmodels’
Package to discover topics.
- Evaluate the model.


SourceCode:
library("tm")
library("slam")
library("topicmodels")
#Load Text
con <- file("tweets.txt", "rt")
tweets = readLines(con)
#Clean Text
tweets = gsub("(RT|via)((?:\\b\\W*@\\w+)+)","",tweets)
tweets = gsub("http[^[:blank:]]+", "", tweets)
tweets = gsub("@\\w+", "", tweets)
tweets = gsub("[ \t]{2,}", "", tweets)
tweets = gsub("^\\s+|\\s+$", "", tweets)
tweets <- gsub('\\d+', '', tweets)
tweets = gsub("[[:punct:]]", " ", tweets)
corpus = Corpus(VectorSource(tweets))
corpus = tm_map(corpus,removePunctuation)
corpus = tm_map(corpus,stripWhitespace)
corpus = tm_map(corpus,tolower)
corpus = tm_map(corpus,removeWords,stopwords("english"))
tdm = DocumentTermMatrix(corpus) # Creating a Term document Matrix
# create tf-idf matrix
term_tfidf <- tapply(tdm$v/row_sums(tdm)[tdm$i], tdm$j, mean) * log2(nDocs(tdm)/col_sums(tdm > 0))
summary(term_tfidf)
tdm <- tdm[,term_tfidf >= 0.1]
tdm <- tdm[row_sums(tdm) > 0,]
summary(col_sums(tdm))
#Deciding best K value using Log-likelihood method
best.model <- lapply(seq(2, 50, by = 1), function(d){LDA(tdm, d)})
best.model.logLik <- as.data.frame(as.matrix(lapply(best.model, logLik)))
#calculating LDA
k = 50;#number of topics
SEED = 786; # number of tweets used
CSC_TM <-list(VEM = LDA(tdm, k = k, control = list(seed = SEED)),VEM_fixed = LDA(tdm, k = k,control = list(estimate.alpha = FALSE, seed = SEED)),Gibbs = LDA(tdm, k = k, method = "Gibbs",control = list(seed = SEED, burnin = 1000,thin = 100, iter = 1000)),CTM = CTM(tdm, k = k,control = list(seed = SEED,var = list(tol = 10^-4), em = list(tol = 10^-3))))
#To compare the fitted models we first investigate the values of the models fitted with VEM and estimated and with VEM and fixed
sapply(CSC_TM[1:2], slot, "alpha")
sapply(CSC_TM, function(x) mean(apply(posterior(x)$topics, 1, function(z) - sum(z * log(z)))))
Topic <- topics(CSC_TM[["VEM"]], 1)
Terms <- terms(CSC_TM[["VEM"]], 8)
Terms
Your site may be amazing and furthermore require awesome open on your blog bit of paper. Not too bad introduction keep engraving. I totally cherished the manner in which you reviewed this put. The substance are written positively and all the wordings are extremely straightforward. This blog is one in my top choice. Continue sharing extra supportive and useful posts. Feel free to visit site Cheap essay writing service...
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThank you so much for this article!
ReplyDeleteI am an absolute newbie to R and topic modeling, I would like to do a LDA analysis on a corpus of 7000+ articles containing a certain term in order to understand the topics associated with said term. I dowloaded the articles and now I have a folder with 53 .html files... from here, I really don't know what to do. I have been looking for manuals, tutorial and explanations but they're all too "basic" (beginner guides to R) or too complex for me (in-depth insights on topic modeling).
I know the theory behind, i.e. what steps are involved in such a topic modeling, but I am having a hard time coding.
Could you help me out?
Some of those taxes and rules are federally regulated and they are therefore consistent across Canada, but a majority of are specific Alberta. canadian mortgage calculator If you do not choose to get CMA PRO, you are able to continue while using the Canadian Mortgage App free of charge forever. mortgage calculator canada
ReplyDeleteHi! I know this is kind of off topic but I was wondering which blog platform are you using for this website? I'm getting sick and tired of Wordpress because I've had issues with hackers and I'm looking at options for another platform. I would be great if you could point me in the direction of a good platform. Stretch mark removal Singapore
ReplyDeletekarabük
ReplyDeletesiirt
niğde
düzce
karaman
0Y4HJF
yurtdışı kargo
ReplyDeleteresimli magnet
instagram takipçi satın al
yurtdışı kargo
sms onay
dijital kartvizit
dijital kartvizit
https://nobetci-eczane.org/
HL350A
Eskişehir
ReplyDeleteDenizli
Malatya
Diyarbakır
Kocaeli
H5İF
görüntülü.show
ReplyDeletewhatsapp ücretli show
MV2G
https://titandijital.com.tr/
ReplyDeletenevşehir parça eşya taşıma
bolu parça eşya taşıma
batman parça eşya taşıma
bayburt parça eşya taşıma
FNEİ5D
antalya evden eve nakliyat
ReplyDeleteankara evden eve nakliyat
bursa evden eve nakliyat
yalova evden eve nakliyat
gümüşhane evden eve nakliyat
YEY1
DDF39
ReplyDeleteRize Şehirler Arası Nakliyat
Ankara Boya Ustası
Bilecik Şehir İçi Nakliyat
Çorum Evden Eve Nakliyat
Eryaman Boya Ustası
Mamak Boya Ustası
Karapürçek Fayans Ustası
Gölbaşı Parke Ustası
Kocaeli Şehirler Arası Nakliyat
CB9F3
ReplyDeleteAdana Evden Eve Nakliyat
Niğde Evden Eve Nakliyat
Gümüşhane Evden Eve Nakliyat
Kütahya Evden Eve Nakliyat
Afyon Evden Eve Nakliyat
buy trenbolone enanthate
Kırşehir Evden Eve Nakliyat
Bayburt Evden Eve Nakliyat
Silivri Parke Ustası
96C4B
ReplyDeleteAfyon Evden Eve Nakliyat
Sinop Şehir İçi Nakliyat
Karapürçek Boya Ustası
Çerkezköy Oto Elektrik
Kırklareli Şehirler Arası Nakliyat
Maraş Şehirler Arası Nakliyat
Elazığ Parça Eşya Taşıma
Ankara Boya Ustası
Tekirdağ Şehir İçi Nakliyat
243FE
ReplyDelete%20 indirim kodu
A6DE3
ReplyDeletemersin ücretsiz sohbet sitesi
sesli sohbet sesli chat
sohbet chat
malatya telefonda kızlarla sohbet
sohbet sitesi
niğde goruntulu sohbet
tunceli canlı sohbet odası
Bartın En İyi Ücretsiz Sohbet Siteleri
rastgele sohbet odaları
CC26D
ReplyDeleteAğın
Çemişgezek
Çelebi
Mazgirt
Hadim
Bayramören
Yayladere
Hozat
Pülmür
59CBB
ReplyDeletepapatya sabunu
en az komisyon alan kripto borsası
rastgele canlı sohbet
paribu
huobi
toptan mum
okex
referans kod
bitcoin ne zaman çıktı
7A61E
ReplyDeletebinance
bitcoin nasıl oynanır
kripto para telegram
4g mobil proxy
binance
btcturk
telegram kripto para
bitcoin nasıl üretilir
bibox
3E588
ReplyDeletebinance 100 dolar
bybit
4g mobil
paribu
kucoin
kraken
bitcoin ne zaman çıktı
mexc
coin nereden alınır
42AF2
ReplyDeletebitcoin nasıl üretilir
binance
poloniex
bitget
bybit
bingx
gate io
February 2024 Calendar
March 2024 Calendar
8BA0F
ReplyDeletewhatsapp ucretli show
Very informative post ! There is a lot of information there. thanks for sharing. Delhi to Kainchi Dham Bus
ReplyDelete11FD6E1CE2
ReplyDeletetelegram show
skype show
cam şov
whatsapp görüntülü show güvenilir
whatsapp ücretli show
whatsapp görüntülü şov
ücretli şov
skype şov
ücretli show
AE79809FEF
ReplyDeleteCialis 5 MG 20 MG 100 MG 600 MG Hap Tablet Krem ve Jel Fiyat ve Sipariş - www.ijuntaxmedikal.store
şov
Steroid Satın Al | Anabolik Steroid | Fiyatlar ve Sipariş | İğne - www.steroidsatinal.online
cialis
steroid satın al
5B90252042
ReplyDeletetwitter takipçi
Kafa Topu Elmas Kodu
Pasha Fencer Hediye Kodu
Brawl Stars Elmas Kodu
Happn Promosyon Kodu
Township Promosyon Kodu
Razer Gold Promosyon Kodu
Osm Promosyon Kodu
101 Okey Vip Hediye Kodu
3F28F7CF41
ReplyDeleteinstagram yabancı gerçek takipçi
twitter beğeni satın al
türk takipçi
bayan takipçi
gerçek takipçi
ReplyDeleteHayat boyunca birçok farklı kitapla karşılaşmak, insanın ufkunu genişletir ve yeni perspektifler kazandırır. Bu nedenle, zaman zaman kitap önerileri alarak okuma listemizi zenginleştirmek faydalı olur. Özellikle, çeşitli türlerdeki kitaplar sayesinde hem eğlenir hem de bilgi dağarcığımızı arttırırız. Her bireyin kendine uygun bir kitap bulması, kişisel gelişim açısından önemlidir. Böylece, kitaplar hayatımızda daha anlamlı ve değerli bir yer tutar.